
출처 : https://blogs.msdn.microsoft.com/psssql/2016/10/04/default-auto-statistics-update-threshold-change-for-sql-server-2016/
Default auto statistics update threshold change for SQL Server 2016
Lately, we had a customer who contacted us for a performance issue where their server performed much worse in SQL Server 2016 following upgrade. To show us as an example, he even captured a video. In the video, he showed that the session that was compiling the query had multiple threads waiting on LATCH_EX of ACCESS_METHODS_DATASET_PARENT. This type of latch is used to synchronize dataset access among parallel threads. In general, it deals with large amount of data. Below is a screenshot from the video. Note that I didn’t include complete columns because I don’t want to reveal customer’s database and user names. This is very puzzling because we should not see parallel threads during true phases of compiling.

After staring at it for a moment, we started to realize that this must have something to do with auto update statistics. Fortunately, we have a copy of pssdiag captured that include trace data. To prove that auto update statistics could have caused the issue, we needed to find some evidence of long running auto update stats event. After importing the data, we were able to find some auto update stats took more than 2 minutes. These stats update occurred to the queries customer pointed out. Below is an example of auto update in profiler trace extracted from customer’s data collection.

Root cause & SQL Server 2016 change
This turned out to be the default auto stats threshold change in SQL 2016.
KB Controlling Autostat (AUTO_UPDATE_STATISTICS) behavior in SQL Server documents two thresholds. I will call them old threshold and new threshold.
Old threshold: it takes 20% of row changes before auto update stats kicks (there are some tweaks for small tables, for large tables, 20% change is needed). For a table with 100 million rows, it requires 20 million row change for auto stats to kick in. For vast majority of large tables, auto stats basically doesn’t do much.
New threshold: Starting SQL 2008 R2 SP1, we introduced a trace flag 2371 to control auto update statistics better (new threshold). Under trace flag 2371, percentage of changes requires is dramatically reduced with large tables. In other words, trace flag 2371 can cause more frequent update. This new threshold is off by default and is enabled by the trace flag. But in SQL 2016, this new threshold is enabled by default for a database with compatibility level 130.
In short:
SQL Server 2014 or below: default is the old threshold. You can use trace flag 2371 to activate new threshold
SQL Server 2016: Default is new threshold if database compatibility level is 130. If database compatibility is below 130, old threshold is used (unless you use trace flag 2371)
Customer very frequently ‘merge’ data into some big tables. some of them had 300 million rows. The process triggered much more frequent stats update now because of the threshold change for the large tables.
Solution
The solution is to enable asynchronous statistics update. After customer implemented this approach, their server performance went back to old level.

Demo of auto stats threshold change
–setup a table and insert 100 million rows
drop database testautostats
go
create database testautostats
go
use testautostats
go
create table t (c1 int)
go
set nocount on
declare @i int
set @i = 0
begin tran
while @i < 100000000
begin
declare @rand int = rand() * 1000000000
if (@i % 100000 = 0)
begin
while @@trancount > 0 commit tran
begin tran
end
insert into t values (@rand)
set @i = @i + 1
end
commit tran
go
create index ix on t (c1)
go
–run this query and query stats property
–note the last_updated column
select count (*) from t join sys.objects o on t.c1=o.object_id
go
select * from sys.stats st cross apply sys.dm_db_stats_properties (object_id, stats_id)
where st.object_id = object_id (‘t’)

–delete 1 million row
–run the same query and query stats property
–note that last_updated column changed
delete top (1000000) from t
go
select count (*) from t join sys.objects o on t.c1=o.object_id
go
select * from sys.stats st cross apply sys.dm_db_stats_properties (object_id, stats_id)
where st.object_id = object_id (‘t’)

–now switch DB compt level to 120
–delete 1 million row
–note that stats wasn’t updated (last_updated column stays the same)
alter database testautostats SET COMPATIBILITY_LEVEL=120
go
delete top (1000000) from t
go
select * from sys.stats st cross apply sys.dm_db_stats_properties (object_id, stats_id)
where st.object_id = object_id (‘t’)

추가 : http://www.sqlservergeeks.com/sql-server-trace-flag-2371-to-control-auto-update-statistics-threshold-and-behavior-in-sql-server/
'Brain Trainning > DataBase' 카테고리의 다른 글
| [MSSQL] Understanding how SQL Server stores data in data files (펌) (0) | 2016.07.06 |
|---|---|
| [MySQL][펌] Graphing MySQL performance with Prometheus and Grafana (0) | 2016.06.22 |
| [MySQL] Graphing MySQL Performance with Prometheus and Grafana [펌] (0) | 2016.06.06 |
| [MSSQL] 50 Important Queries in SQL Server (0) | 2016.06.06 |
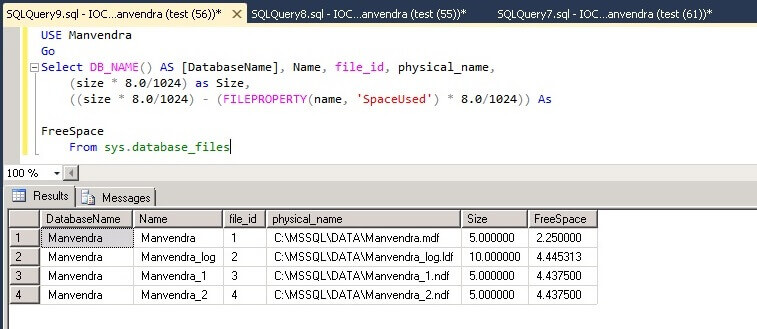
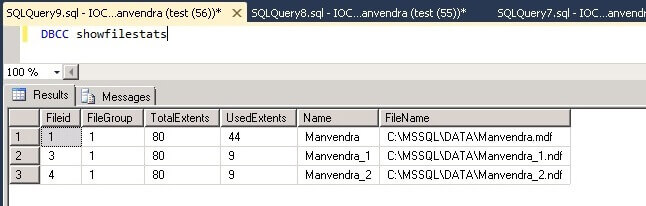
| [MSSQL] DB의 모든 테이블 용량 확인 (0) | 2016.04.27 |




































 Query 17: Get Current Language Id
Query 17: Get Current Language Id






























