http://www.sqlservercentral.com/articles/SQL+Server+2012/86920/
SQL Server 2012 Active/Active Cluster in Hyper-V
By Paul Brewer, 2012/02/13


 Briefcase
Briefcase


There are a few reasons you might want a virtual, Active/Active SQL Server 2012 Cluster. These might include:
- Rather than dynamic and ever expanding VM's or static VM's always under resource pressure, offload the database and log files to a dedicated file server. Alleviate disk pressure from the Hyper V host
- To simulate scenario's and test changes prior to making change in production.
- Self development and training - My motive here.
- Virtual clustering of Windows Server and SQL Server offers the high availability of clustering with the managability of virtualization.
The diagram below shows one possible configuration, used here, but there are many other possibilities.
 A SAN is hosted on a dedicated file server where the iSCSI Target is serving the following disk resources to the 2 cluster servers:
A SAN is hosted on a dedicated file server where the iSCSI Target is serving the following disk resources to the 2 cluster servers:
- SQL Log 1 - Logs for 1st SQL cluster service
- SQL Data 1 - Data for 1st SQL cluster service
- SQL Log 2 - Logs for 2nd SQL cluster service
- SQL Data 2 - Data for 2nd SQL cluster service
- Quorum - For the Windows Cluster Service
A domain controller is providing Active Directory services. The 4 servers above are virtual and hosted in Hyper-V.
HYPER V
The Hyper V host has 8 GB of RAM, 8 processors. Resources are granted to the VM's as follows:
- Domain Controller – 1 GB RAM, 1 CPU
- File Server – 1 GB RAM, 1 CPU
- Cluster Server 1 – 2 GB RAM, 2 Processors
- Cluster Server 2 – 2 GB RAM, 2 Processors
Three virtual networks were created as follows:
ServerName | Role | LAN | SANNET | ClusterPing |
GSPIT002A-DC | Domain Controller | 192.168.1.80 | ||
GSPIT002A-CD | iSCS SAN | 192.168.1.85 | 10.10.10.10 | |
GSPIT002A-CL1 | Cluster 1 | 192.168.1.86 | 10.10.10.11 | 192.168.0.1 |
GSPIT002A-CL2 | Cluster 2 | 192.168.1.87 | 10.10.10.12 | 192.168.0.2 |
In the real world, NIC's might be teamed and there would probably be a dedicated network for backup and TempDB. I'm honestly not sure whether it would be worth hosting TempDB on a dedicated drive or not. All data IO is over TCP and iSCSI with this all occurring within a virtual virtual network using virtual storage so in this case I don't think so.
The following actions then need to be performed but describing the steps is beyond the scope of this but there is plenty of good reference material available.
- Installing and configuring Windows Server 2008 R2 on a Hyper-V VM, apply patches
- Sysprep the image
- Create 3 new VM's from the image
- Promote 1 to a domain controller
- Add the other servers to the domain
- Ensure network settings on servers are as above.
Configure the SAN Storage on the VM's
Clustering relies on a SAN and the Microsoft iSCSI Target can be downloaded for free here: http://www.microsoft.com/download/en/details.aspx?id=19867 and used to create the necessary shared storage.
Install the iSCSI Target on file server GSPIT002A-CD. First create the iSCSI Targets as below:

Then create and assign Devices (Drives) for the iSCSI Target as below:

You need to specify which initiators have permission to the iSCSI Target as below:

Then, right click and disable all but the Quorum iSCSI target, as below:

The iSCSI Initiator is part of Windows Server 2008 so no download is required to configure the cluster iSCSI clients.
Check The 'Initiator Name' of intiaitors as below:

This is needed by the iSCSI Target for permissions.
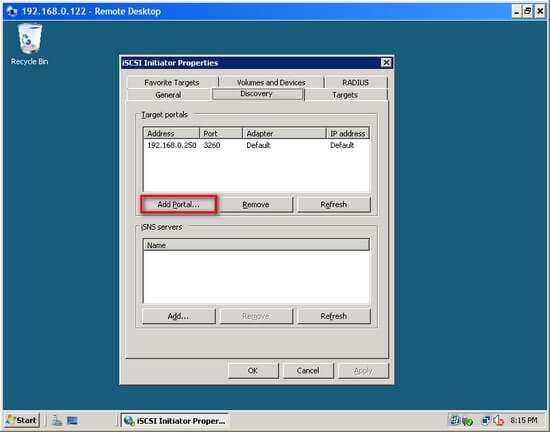
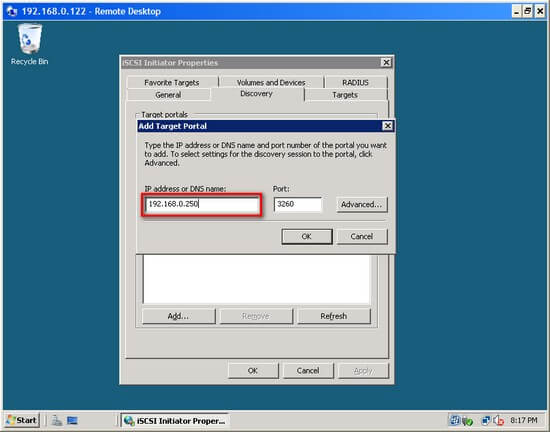
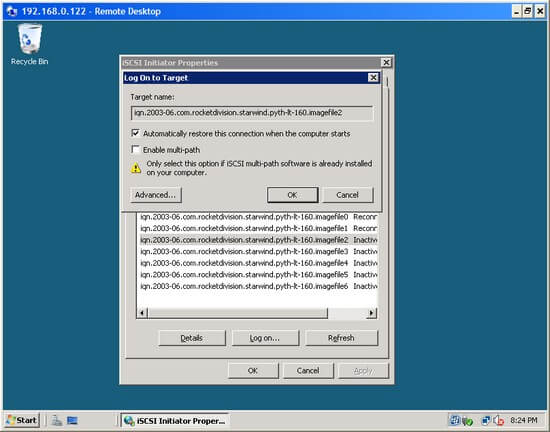
Point the iSCSI Initiator at the iSCSI Target as below:

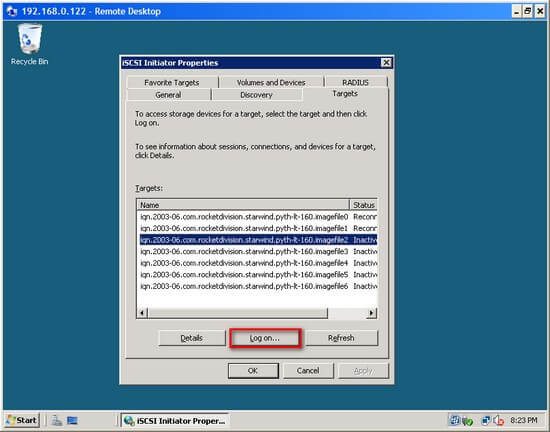
Once the iSCSI Initiator and Target are communicating properly, there is a 'Refresh' button in the 'Discovery' tab and 'Auto Configure' button in the 'Volumes and Devices' tab that make the rest easy.
Configure Windows Clustering
You now need to connect to the clustered server VM's and configure Windows Clustering. First install the 'Failover Clustering' feature on both cluster servers, also install the '.NET Framework 3.5.1 features' too.
Next, mount the Quorum drive using the server 'Disk Manager' as below, right clicking Disk 3 and 'Online':

This can be done on either of the servers that are about to be clustered. Change the Drive letter to 'Q' and rename the volume 'Quorum'
Next, start the 'Administrator' - 'Failover Cluster Manager' snapin and run the 'Validate a Configuration Wizard' to check the setup. This needs to be spot on as if Windows Clustering isn't working, SQL Cluster Services will not work either. Ensure a full set of ticks on the cluster validation wizard before launching the clustering wizard to actually create the cluster. Don't be scared to evict servers from the cluster, destroy the cluster, delete cluster object in Active Directory Computers container, remove then add the cluster feature from servers until you get it spot on.
Use the following settings during the cluster installation:

Install two SQL SERVER 2012 Active/Active cluster nodes
For both Servers, as a prerequisite, install the .NET Framework 3.5.1 Features.
Install first clustered SQL Instance:
- GSPIT002A-CD -On the file server GSPIT002A-CD, enable the iSCSI Target iSCSI Target 'SQL1'.
- GSPIT002A-CL1 - 'Refresh Targets', 'Connect' and 'Auto-Configure volumes and Devices'
- GSPIT002A-CL1 - Using the 'Device Manager', the same same way as the Quorum drive, 'Bring Disks Online', assign Drive Letters and Volume Names
- GSPIT002A-CL1 - SQL Installation Media / Create New Failover Cluster Installation (Service = SQL-CL1, Instance = I1)
- GSPIT002A-CL2 - On the second server - SQL Installation Media / Add as node to existing Cluster
Install second clustered SQL Instance:
- GSPIT002A-CD -On the file server GSPIT002A-CD, enable the iSCSI Target iSCSI Target 'SQL2'.
- GSPIT002A-CL2 - 'Refresh Targets', 'Connect' and 'Auto-Configure volumes and Devices'
- GSPIT002A-CL2 - Using the 'Device Manager' 'Bring Disks Online', assign Drive Letters and Volume Names
- GSPIT002A-CL2 - SQL Installation Media / Create New Failover Cluster Installation (Service = SQL-CL2, Instance = I2)
- GSPIT002A-CL2 - On the first server - SQL Installation Media / Add as node to existing Cluster
I didn't actually reference any blogs to do this and went with a Next, Next, Next approach at the installation wizard. If you are careful, set service accounts, database file locations etc carefully, its straight forward. The sequence of steps to perform actions in was the most difficult aspect which is why the two simple 1...5 lists above are perhaps the best documentation. You should at this point have a fully functioning Active /Active SQL Server 2012 cluster up and running.
Jose Barret blog on iSCSI setup, my primary reference resource in this project.
http://blogs.technet.com/b/josebda/archive/2011/04/04/microsoft-iscsi-software-target-3-3-for-windows-server-2008-r2-available-for-public-download.aspx
'Brain Trainning > DataBase' 카테고리의 다른 글
| [MSSQL] Stairway to SQL Server Indexes (펌) (0) | 2012.02.17 |
|---|---|
| [MSSQL] How to Document and Configure SQL Server Instance Settings (펌) (0) | 2012.02.14 |
| [MSSQL] SQL Server Hardware 관련 좋은 책 한권... (0) | 2012.02.13 |
| [MSSQL] Backup VLDB Over Network (MS Case Study 자료) (0) | 2012.02.13 |
| [Oracle] Load Generator For Oracle - Swingbench (0) | 2012.02.12 |
 FailClust_StepbyStep.doc
FailClust_StepbyStep.doc